Open Source LLM Evaluation for EzMyGo
EzMyGo is an AI-powered travel planning application that generates complete itineraries using a multi-stage AI pipeline. The workflow includes basic schedule generation, hotel selection, activity planning, restaurant recommendations, itinerary merging, and structured output generation. Initially, the entire pipeline used OpenAI’s GPT-4o model, which produced strong results but also resulted in high API usage and operational cost due to multiple sequential LLM calls per itinerary.
To reduce cost while maintaining itinerary quality, an experiment was conducted using open-source LLMs through Ollama. The objective was to replace only the first stage i.e., the Basic Schedule Generator with a locally hosted model, while continuing to use GPT-4o for downstream reasoning-heavy stages such as hotel, activity, and restaurant selection.
The updated architecture became:
Ollama-hosted open-source model → Basic Schedule Generation
GPT-4o → Remaining itinerary pipeline
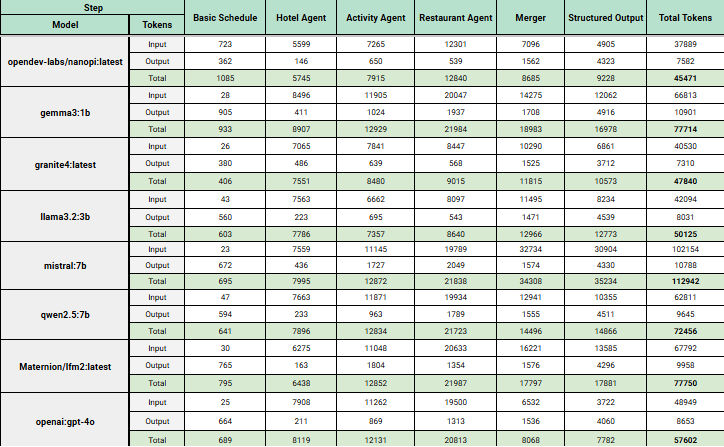
Ollama was selected because it provides lightweight local inference with simple API integration and support for quantized GGUF models. Several open-source models were evaluated, including Gemma 3 1B, Granite 4, Llama 3.2 3B, Mistral 7B, and Qwen 2.5 7B.
The evaluation focused on itinerary quality, timing feasibility, activity sequencing, meal placement, and consistency with the original schedule. Overall, the open-source models performed well for generating the initial itinerary structure. Check-in and checkout timing quality was consistently strong, travel feasibility was generally acceptable, and hotel/activity alignment remained usable across most tests.
However, some limitations were observed. Meal sequencing and filler/free-time handling was less polished compared to GPT-4o, and most models struggled to strictly preserve the original schedule structure. Interestingly, GPT-4o also occasionally modified schedules creatively instead of following the original plan exactly, suggesting that workflow and prompt constraints are equally important factors.
Performance metrics showed complete itinerary generation times ranging from approximately 2 minutes 7 seconds to 4 minutes 54 seconds, depending on the model and itinerary complexity. Token usage also varied significantly across models, with the largest usage occurring during restaurant generation, activity planning, and structured output formatting. The findings showed that replacing even a single upstream GPT-4o stage with a local model could meaningfully reduce API cost at scale.
Alongside inference testing, research was conducted into fine-tuning open-source models for future self-hosted deployment. The research focused on commonly used base models such as LLaMA, Mistral, Qwen, Phi, and TinyLlama. The study also explored parameter-efficient fine-tuning techniques such as LoRA and QLoRA, which train lightweight adapter layers instead of retraining entire models, significantly reducing GPU requirements.
The research concluded that a practical future direction for EzMyGo would be to build a domain-specific travel dataset and fine-tune a lightweight open-source model specialized for itinerary generation. The workflow would involve dataset preparation, LoRA/QLoRA training, GGUF conversion, and deployment through Ollama for local inference.
Overall, the exercise demonstrated that a hybrid AI architecture is practical for EzMyGo. Open-source LLMs are now capable of handling foundational itinerary generation tasks effectively, while GPT-4o can continue to power the more advanced reasoning and refinement stages. This approach provides a balance between quality, scalability, and operational cost reduction.